
By Alex Dunstan-Lee
Our work with Generative AI is helping clients to unlock significant cost savings in eDiscovery. But, as excitement builds, is this a sign that the latest new wave of technological development will deliver lasting transformative change?
Chat GPT, Gemini, Co-Pilot, Deepseek have, almost overnight, become household names. Generative AI based on Large Language Models has brought AI into the mainstream. It has upended the way we interact with large data sets and brought an ability to generate human-like content in a way not seen before.
Of course, existing business software solutions have been racing to embed their own versions of this technology into their software platforms – from finance to HR and legal. There is barely a business process that will be left untouched by this technology.
However, AI hype has come before, with real change occurring more slowly. In the world of eDiscovery - that is the handling of large data sets in legal disputes, investigations and regulatory inquiries - AI techniques have been available for more than a decade. Yet, take-up has often been slow. In this piece, I explore previous waves of new technology in eDiscovery so we can better understand our initial experiences of using the latest Gen AI.
The burning question is whether the new wave of functionality will suffer from objections around cost and user reticence as before in previous waves? Initial reaction from our clients using the new functionality, both in eDiscovery and across business services in general, suggests that this time it really is different.
The first wave: concept mapping and predictive analytics
In 2006, I gave my first presentation on eDiscovery, trying to persuade lawyers to use advanced technology to speed up document review. I used an animation to depict a banker’s box opening and documents magically separating into piles based on their topic or relevance. This, I would assert, was how to think of the technology. Instead of having paralegals and junior lawyers doing the initial sift of the documents and putting them into piles based on topics or relevance, this ‘concept-mapping’ technology would do it for you. Why would you not give that a try?
For lots of reasons, it turned out. One was the cost of processing the data: over £1000 per GB at that time for the more advanced technology (compared to costs for similar processing of £20 per GB or considerably less today). Another factor was the cultural shift required to embrace this sort of technology. The sense of discomfort in the idea that a machine might be making decisions instead of humans, however misguided that interpretation might be, would not change overnight. The juggernauts of the major law firms, charging high hourly rates for their junior lawyers reviewing countless irrelevant documents, were not motivated to change.
This was the start of what I think of as the first wave of AI (machine-learning and advanced analytics) in the world of disputes and investigations. It was exciting, there was a lot of interest, and it made for a great demo. However, while lawyers started to use electronic platforms for document for review, the use of the most advanced analytics capabilities such as concept mapping/clustering was very limited.
The second wave: predictive coding and technology assisted review (“TAR”)
Building on the techniques of before, predictive coding or TAR involved training the machine to replicate the decision making of the lawyers - as lawyers review, the machine would spot patterns in what gets marked as relevant and start to make predictions as to whether unreviewed documents would be relevant or not.
At first, there were arguments about whether a judge would need to understand the specific workings of the algorithm used to perform this exercise. Predictive coding was endorsed in the US courts as early as 2012 and reinforced in Rio Tinto Plc v. Vale S.A., 1:14-cv-3042 (S.D.N.Y. Mar. 2, 2015) when Magistrate Judge Adrew Peck remarked that “the case law has developed to the point that it is now black letter law that where the producing party wants to utilize [TAR] for document review, courts will permit it."
A decision of the English High Court was then handed down in 2016 expressly approving the use of predictive coding/TAR for a large disclosure exercise (Pyrrho Investments Limited & Anr v MWB Property Limited and Others [2016] EWHC 256 (Ch)).
Some felt that judicial acceptance was the turning point for the use of this sort of technology. I would argue that the reduction in cost was at least as important.
At this time, software providers were still trying to recover their development costs by charging additional fees for advanced analytics and TAR. eDiscovery service providers had some nice ROI scenarios to show how, by spending more on the technology, vast amounts could be saved on the legal review costs. But it was hard to predict the cost saving with any certainty. Legal review costs were dropping dramatically over this period, with the growth and acceptance of first level review being outsourced to lower cost resources onshore and offshore. Clients were more comfortable focusing on cost savings from cheaper (human) reviewers rather than cutting the scale of the review effort through expensive-sounding AI functionality.
However, over time, the use of TAR did increase, and this accelerated as the cost of the functionality became embedded in the standard pricing. Many review platforms started to introduce functionality that would learn in the background – i.e. track what reviewers were doing and start making relevance predictions on unreviewed documents – even if the user did not want to use or interact with that functionality directly. Consequently, it became common to use this ‘active learning’ technology for quality control, prioritisation and increasingly, for discounting sets of documents which were well below the relevance threshold.
The third wave: Generative AI, Natural Language Processing and Large Language Models
By 2022, the year when ChatGPT was born, AI in the form of active learning had become a cost-effective and widely accepted way of making document review more efficient. Through 2023/4, it seemed that every software company was introducing some sort of GenAI module into its applications. Relativity announced their platform - Relativity aiR, based on GPT-4 - in 2023 and scheduled it for release in 2024. At Rel Fest in the UK in 2024 there was huge excitement about aiR (I got a t-shirt).
It felt to me that we were at the start of what Gartner refers to as the ‘Hype Cycle’ which posits that there is a common pattern that innovations experience – as described in the diagram.
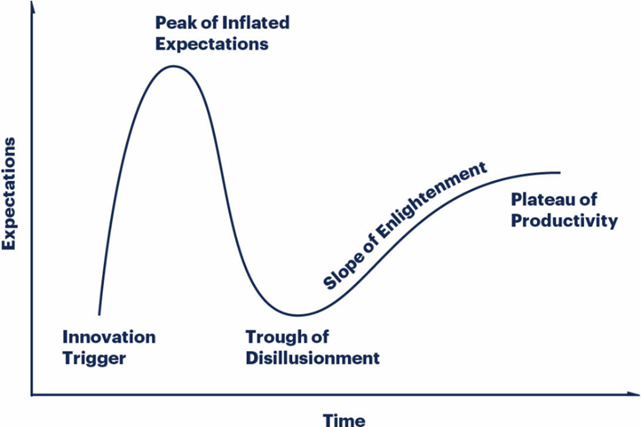
I wondered if we were currently at the ‘Peak of Inflated Expectations’ and about to slide into the ‘Trough of Disillusionment’. My concerns were not about the new functionality itself, which I could see was powerful, but that a) it comes with an additional cost and b) we already have the powerful pattern-recognition form of AI referred to above (at less cost). Would the new version really offer enough advantage over the old to justify the cost?
The first sign that something might be different came soon after Relativity launched aiR in the UK. Lawyers started to ask about GenAI. Not just the lawyers but their clients. And so, within weeks of the launch of the technology, we had two cases actively using GenAI.
It's early days but the signs are good. On one case, we are using Relativity aiR to conduct the sole first pass review – no human involvement. The cost of running documents through Relativity aiR was less than £10k compared to an estimated first pass review human review cost of over £50k.
These cases are ongoing, and we continue to hone the methodology in different ways on each case. When the dust has settled, I hope we can provide a more detailed case study showing our learnings. It is not a simple, push-button exercise. It’s clear that, even more than before, this is a new form of art. The technology is powerful, but the humans involved (our team and the lawyers) are essential too. We are learning skills which will be critical in the proper and efficient use of AI.
For example, what does a good AI prompt look like? Ironically, we are using another form of AI (Co-pilot) to simplify the legalistic prompts provided by the lawyers so that we can use language that gets the best out of the AI. It’s a highly iterative and nuanced process between humans and technology. In effect, we are designing a document review protocol – training instructions that might be given to a team of paralegal reviewers – except we are training the technology instead. As a former lawyer, watching these (much younger!) lawyers interact with this new capability, training it almost as you might a human, it does suggest that the game has changed.
We’ve had senior lawyers objecting that this sort of technology has not yet been tested in the courts. Do we need a run of case-law, akin to that for predictive coding referred to above, to provide reassurance on the use of this technology? I would argue that the fundamentals of those earlier cases – ultimately that if you can use technology to enhance your disclosure exercise then you should do so – apply to this new technology. We don’t need to go over old ground; it was clear in those cases that the Court is not the place to debate the inner workings of the technology. The focus is much more likely to be on how the parties go about agreeing the methodology in advance. In this sense the new technology can be thought of as an advanced form of search. As noted in Agents' Mutual Ltd v Gascoigne Halman Ltd [2019] EWHC 3104 (Ch),
"Because electronic searches have the effect of determining the scope of subsequent, more intense and probably manual reviews, it is imperative that such electronic searches not be conducted unilaterally, but with the parties engaging with each other with a view to agreeing precisely how the electronic search is to proceed."
The judge recognised that the process should be undertaken in "an iterative and co-operative way" – which is a perfect way to describe the process for using the AI effectively - and he said it is important to complete this process before the manual review.
However, finding agreement between two sides on the parameters of more complex forms of review can be difficult. We’ve often adopted an advanced, efficient review process using the machine-learning technology, only for this to lead to a lot of back-and-forth between the two sets of lawyers. After seeing lengthy letters going between the two legal teams, defending their methodologies, I’m sometimes left wondering whether it might have been cheaper to have had low-cost reviewers just do a page-by-page document review from the start and avoid all the fuss.
However, the new form of ‘training’ the technology is much closer to the concept of training a human, rather than being based purely on statistics; perhaps those training instructions will be easier to agree. A critical difference now is that the technology can explain exactly why it made a particular decision about a document – and this iterative process feels much more like human discourse. Lawyers are famed for being technophobes, but the new capability has humanised the interaction with the technology, and I believe this is a step change for the legal profession.
Summary
There seem to be two fundamental changes occurring which suggest a paradigm shift, which impacts eDiscovery as well as the use of this type of AI in other business environments:
In eDiscovery, these factors are reinforced by the fact that the technology can put the control back in the hands of the senior lawyers and reduce outsourcing to low-cost review teams. The application of the art of Gen AI becomes something that law firms can sell. And, for the AI fear mongers (‘AI will take our jobs’), the technology creates a need for new valuable skills and services.
Time will tell whether Gen AI in eDiscovery is better in fact (i.e. notably cheaper overall for similar levels of quality and productivity) than TAR and/or low-cost human review teams. The answer will likely be that ‘it depends’ – on the case, on the other side, on the lawyers. It will always be difficult to know for sure upfront and so it will be a judgement call (by a human). In any event perhaps the question of whether it is truly better simply does not matter – the shift towards Gen AI will occur regardless, because human beings like using it.
So, for now, do believe the hype – there are hurdles to get over, but for those of us in the business of combining humans and technology to provide services, the excitement continues. The trough of disillusionment is nowhere to be seen.
